Minor Mistake, Major Catastrophe – GitLab Goes Offline For a Day
GitLab, a startup that is an alternative to the highly popular GitHub, has had a rather rough day recently as a human error caused the whole website to be down for a full day.
Read Also: 10 Useful Github Features to Know
GitLab’s problem first began when the website was experiencing load time and stability problems. The website was brought offline in order to rectify the issues. However, during the maintenance, someone unwittingly made the mistake of accidentally deleting a directory containing 300GB of live production data.
Fortunately for GitLab, the contents that were deleted only affected issues and merged requests. The repositories and wikis were not affected by this mistake in any way, meaning that the damage caused by this mistake was not as severe as it could have been
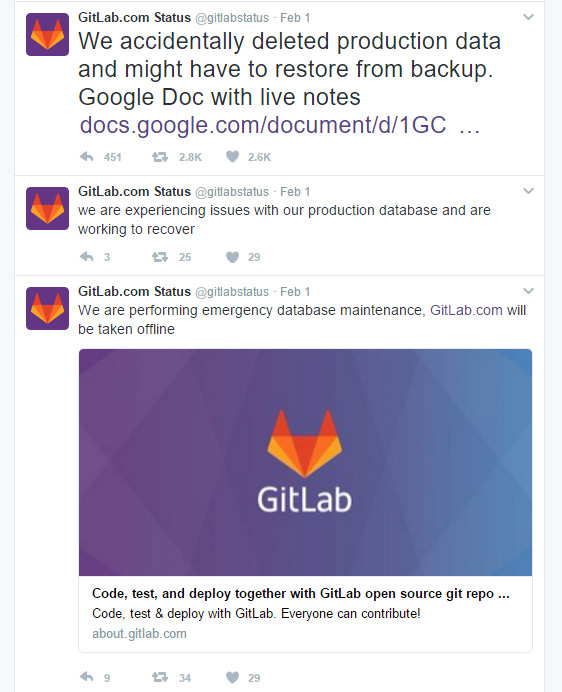
With the directory deleted, the GitLab personnel immediately turn towards its backup. Unfortunately for them, GitLab ran into yet another problem. According to the Google Doc file that was constantly being updated as GitLab struggles to get back online, all 5 backup/replication techniques that the website deployed failed to work reliably, and in some cases were never set up in the first place.
Retrieving these lost files from the cloud is not an option for GitLab either as the startup decided late last year to dump the cloud in order to build and operate its own Ceph clusters instead. Needless to say, GitLab is now reconsidering their stance on that particular topic.
@TheRegister @gitlab will be working on making the application more performant and exploring alternative cloud hosting providers.
— Connor Shea (@connorjshea) February 1, 2017
Despite the tumultuous day that GitLab has had, the website is now up and running as per normal. While the website reported that some data was lost during a six-hour window, the Git repositories were left unharmed throughout the entire ordeal. A full incident log of the entire event can be viewed here.
While many lessons can be learned from GitLab’s little mistake (mainly hubris), GitLab’s method of handling the crisis is rather admirable as the startup was clear and transparent with its users. Here’s to hoping that GitLab learns from this mistake. Otherwise, its user base would probably be less forgiving if history repeats itself.
Source: The Register
Read Also: Using Git on Android – Free Tools and Guide