How to Run LLM in Docker
Large Language Models (LLMs) have changed how we build and use software. While cloud-based LLM APIs are great for convenience, there are plenty of reasons to run them locally, including better privacy, lower costs for experimentation, the ability to work offline, and faster testing without waiting on network delays.
But running Large Language Models (LLMs) on your own machine can be a headache as it often involves dealing with complicated setups, hardware-specific issues, and performance tuning.
This is where Docker Model Runner comes in. At the time of this writing, it’s currently in Beta, it is designed to simplify everything by packaging LLMs in easy-to-run Docker containers.
Let’s see how it works.
Requirements
Requirements differ depending on your operating system. Below are the minimum requirements for running Docker Model Runner.
| Operating System | Requirements |
|---|---|
| macOS |
|
| Windows |
|
Enabling Docker Model Runner
Once you have met the requirements, you can proceed with the installation and setup of Docker Model Runner with the following command.
docker desktop enable model-runner
If you want to allow other apps to connect the Model Runner’s endpoint, you’ll need to enable TCP host access on a port. For example, to use port 5000:
docker desktop enable model-runner --tcp 5000
This will expose the Model Runner’s endpoint on localhost:5000. You can change the port number to any other port you prefer or available in your host machine. The API is also OpenAI-compatible, so you can use it with any OpenAI-compatible client.
Running a Model
Models are pulled from Docker Hub the first time you use them and will be stored locally, similar to a Docker image.
Let’s say we want to run Gemma3, a quite powerful LLM from Google that we can use for various tasks like text generation, summarization, and more. To run it, we first pull the following command:
docker model pull ai/gemma3
Similar to pulling a Docker image, if the version is not specified, it will pull the latest version or variant. In our case, this would pull the model with 4B parameters and 131K context length. You can adjust the command to pull a different version or variant if needed, such as ai/gemma3:1B-Q4_K_M for the 1B version with quantization.
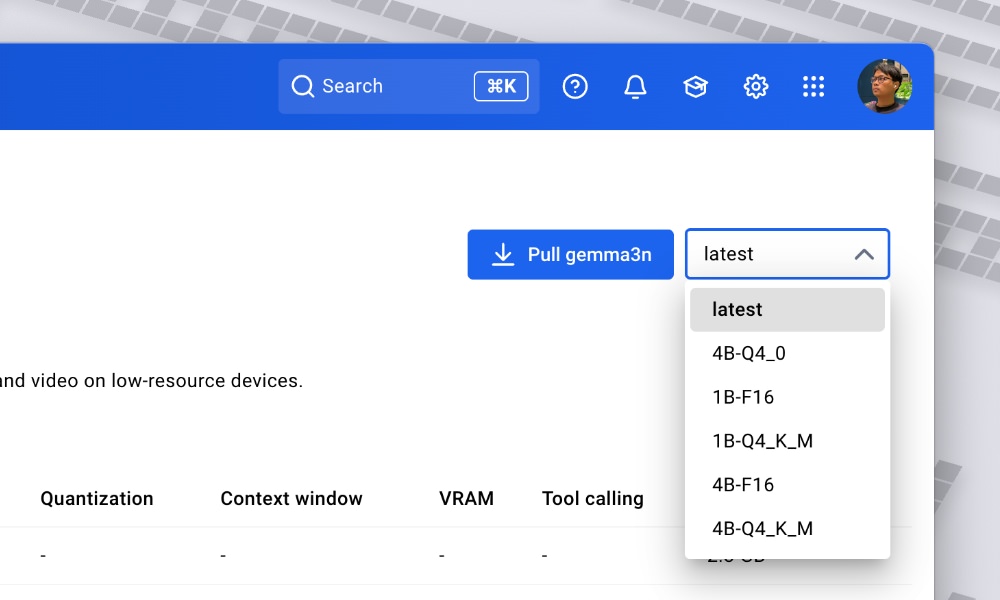
Alternatively, you can click the “Pull” from the Docker Desktop, and select which version you’d like to pull:
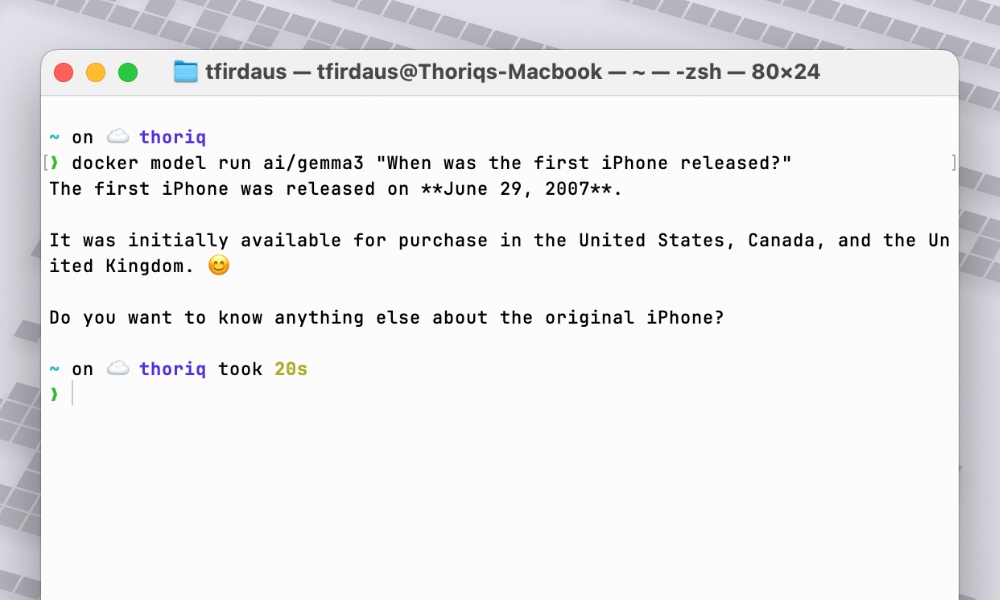
To run the model, we can use the docker model run command. For example, in this case, I’d ask it a question about the first iPhone release date:
docker model run ai/gemma3 "When was the first iPhone released?"
Sure enough it returns the correct answer:
Running with Docker Compose
What’s interesting here is that you can also use and run the models with Docker Compose. So instead of just running a model by itself, you can define the model alongside your other services in your compose.yaml file.
For example, assume that we want to run a WordPress site, and we also want to use the Gemma3 model for text generation to allow us to generate draft blog posts and articles quickly within our WordPress. We can arrange our compose.yaml, like this:
services:
app:
image: wordpress:latest
models:
- gemma
- embedding-model
models:
llm:
model: ai/gemma3
As mentioned, the Model’s endpoint is accessible both internally within the connected services in the Docker network and externally from your host machine, as shown below.
| Access | Endpoint |
|---|---|
| From Container | http://model-runner.docker.internal/engines/v1 |
| From Host machine | http://localhost:5000/engines/v1, assuming you set the tcp port to 5000 |
Since the endpoint is OpenAI-compatible, you can use it with any OpenAI-compatible client such as the official SDK libraries. For example, below is how we could use it with the OpenAI JavaScript SDK.
import OpenAI from "openai";
const client = new OpenAI({
apiKey: "",
baseURL: "http://localhost:5000/engines/v1",
});
const response = await client.responses.create({
model: "ai/gemma3",
input: "When was the first iPhone released?"
});
console.log(response.output_text);
And that’s it! You can now run LLMs in Docker with ease, and use them in your applications.
Wrapping up
Docker Model Runner is a powerful tool that simplifies the process of running Large Language Models locally. It abstracts away the complexities of setup and configuration, especially if you’re working with multiple models, services and team. So you and your team can focus on building applications without worrying much on the underlying setup or configuration.